“If programming is magic, then web scraping is wizardry; that is, the application of magic for particularly impressive and useful-yet surprisingly effortless-feats.”
~ Ryan Mitchell
hkaLabs: hkalabs.com – Web/Screen Scraping adalah metode untuk mengekstrak informasi (tekstual maupun non tekstual) dari website atau layar, sehingga dapat dianalisis lebih lanjut. Bisakah kita mendapatkan informasi-informasi tersebut hanya dari copy-paste manual? Tentu sangat bisa! Singkatnya, manfaat web scraping adalah memungkinkan kita untuk mengotomatisasi dan mempercepat proses pengumpulan data tersebut, apalagi jika pengumpulan data dalam jumlah banyak dan harus dilakukan lebih dari satu kali.
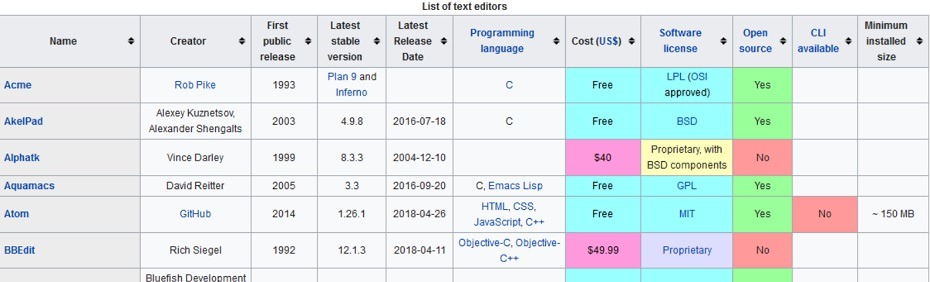
Salah satu pekerjaan yang sering ditemukan dalam web scraping adalah meretrieve data dari HTML table dan menyimpannya dalam format CSV (comma separated values). Di postingan kali ini, kita akan scrape data dari Wikipedia’s Comparison of Text Editors; yang merupakan contoh yang bagus, karena tabel HTMLnya cukup kompleks, dan juga terdapat dua belas tabel pada artikel ini (bayangkan jika kita harus copy-paste secara manual!).
Sudah dibuka link text editornya? Kita dapat scrape tabel pertama hanya dengan python script yg kurang dari 20 baris berikut ini:
import csv
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('https://en.wikipedia.org/wiki/Comparison_of_text_editors')
bsObj = BeautifulSoup(html, 'html.parser')
#The main comparison table is currently the first table on the page (index [0])
table = bsObj.findAll("table", {"class":"wikitable"})[0]
rows = table.findAll("tr")
csvFile = open("../wswp/files/editors.csv", 'w+')
writer = csv.writer(csvFile)
try:
for row in rows:
csvRow = []
for cell in row.findAll(['td', 'th']):
csvRow.append(cell.get_text())
writer.writerow(csvRow)
finally:
csvFile.close()
Script di atas akan menghasilkan file CSV yang telah terformat dengan baik, dan akan tersimpan local di ../files/editors.csv, siap untuk diolah lebih lanjut maupun dibagikan ke pihak yang membutuhkan. 🙂
See it in Action
Sesuai judul blog ini, after we type it (or copy-paste it), just run it! See it in action! 🙂
Penampakan running script dengan Anaconda Prompt:

Penampakan running script di Spyder:

Belum pernah pakai python dengan Anaconda/Spyder? Cobalah saudara-saudariku, karena cocok sekali untuk keperluan Data Science. Berisikan 1000+ Data Science packages, yang sangat mudah diinstall dengan conda, maupun Anaconda Navigator. Bahkan ketika kita install Spyder, scikit-learn (Machine Learning package), bs4/Beautiful Soup; packages untuk web scraping yang kita bahas di artikel ini telah menjadi package bawaan. Mau pakai TensorFlow? Just few click away to install, with Anaconda Navigator. 🙂
Saudara-saudari bebas running script pakai yg mana, kalau saya prefer anaconda prompt karena ringan ketika buka aplikasi di awal. Yang penting, perhatikan working directorynya ya. 😀
Kok seperti tidak muncul apa-apa di console? Eits, lihat dulu ke ../files/editors.csv di working directory anda. Akan ada file editors.csv di sana.
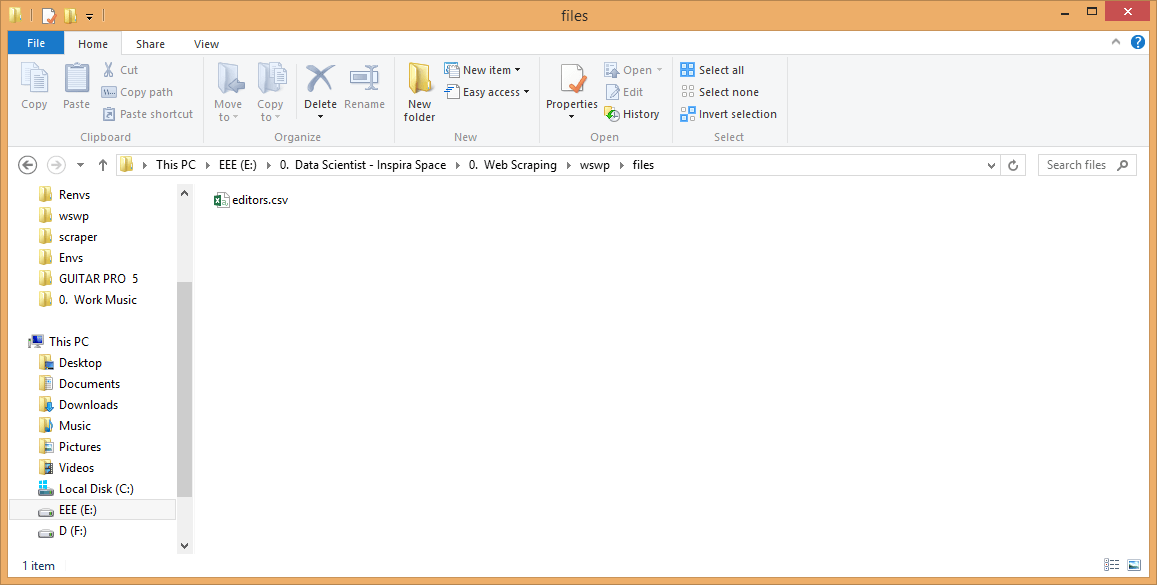
Buka file tersebut, dan tada! Data yang anda idamkan telah tersimpan dengan baik di sana, dan siap diproses sesuai kebutuhan anda. 😀

Explanation
Sedangkan, untuk yang tidak puas dengan copy-paste saja, berikut ini penjelasan singkatnya:
import csv from urllib.request import urlopen from bs4 import BeautifulSoup
Import libraries yang kita butuhkan:
- csv: untuk bekerja dengan file CSV
- urllib: untuk menghandle URL
- bs4: untuk mengambil data dari file HTML maupun XML.
html = urlopen('https://en.wikipedia.org/wiki/Comparison_of_text_editors')
bsObj = BeautifulSoup(html, 'html.parser')
Jika ingin scraping tabel dari URL lain di Wikipedia, silakan ganti saja URL di dalam urlopen(), seperti yang nanti saya demonstrasikan di bagian Bonus.
#The main comparison table is currently the first table on the page (index [0])
table = bsObj.findAll("table", {"class":"wikitable"})[0]
rows = table.findAll("tr")
Sementara itu, untuk scraping data pada tabel, menggunakan method .findAll() pada BeautifulSoup. .findAll() adalah salah method yang paling populer pada BeautifulSoup, karena memungkinkan kita mencari bagian yang paling kita inginkan dari file HTML, yah seperti fitur search begitulah kira-kira.
Pada kasus scraping tabel HTML Wikipedia ini, method .findAll() kita gunakan untuk scraping data pada tag “table” dengan class: wikitable, dan tag “tr” untuk menarik data dari baris tabel. Sementara itu, karena tabel yang kita inginkan adalah tabel pertama pada halaman web, maka kita gunakan indeks [0] (ingat bahwa indeks pertama pada python adalah 0, bukan 1).
csvFile = open("../wswp/files/editors.csv", 'w+')
writer = csv.writer(csvFile)
Next, kita buat file CSV untuk tempat kita menyimpan data hasil scraping (editors.csv), yang bisa diakses di working directory /files. w+ pada open() berfungsi untuk writing data ke dalam file editors.csv.
try: for row in rows: csvRow = [] for cell in row.findAll(['td', 'th']): csvRow.append(cell.get_text()) writer.writerow(csvRow) finally: csvFile.close()
Berikutnya, method .get_text() digunakan untuk mengekstrak data. Dengan “td” adalah tag table data/cell, dan “th” adalah table header. Detil lebih jauh tentang HTML table tag, bisa dibaca di referensi di bawah. 🙂
Lalu proses berikutnya adalah menyalin data satu persatu, yang diiterasikan hingga baris terakhir, lalu ditulis ke dalam file CSV.
Bonus
1. Saya ingin scrape tabel yang kedua Gan, saya butuh data Operating System Supportnya, gimana?
Gampang Gan, anda tinggal ganti indeks [0] jadi [1]. Contoh:
#The main comparison table is currently the second table on the page (index [1])
table = bsObj.findAll("table", {"class":"wikitable"})[1]
rows = table.findAll("tr")
2. Saya ingin scrape tabel dari List of Cryptocurrencies, Gan. Bukan Wikipedia’s Comparison of Text Editors, gimana?
Gampang juga Gan, tinggal ganti URLnya saja jadi https://en.wikipedia.org/wiki/List_of_cryptocurrencies. Contoh:
html = urlopen("https://en.wikipedia.org/wiki/List_of_cryptocurrencies")
bsObj = BeautifulSoup(html, 'html.parser')
Upss.. Error ya? Hahaha.. 😀
Tenang, tinggal tambahkan .encode(“utf-8”) saja, pada:
csvRow.append(cell.get_text().encode("utf-8"))
Hasilnya? silakan download di mari. 🙂
3. Saya inginnya file JSON Gan, bukan CSV, ya dua-duanya bolehlah. Gimana?
Silakan copas saja script di bawah ini Gan:
import csv
import json
csvfile = open("../wswp/files/editors.csv", 'r')
jsonfile = open("../wswp/files/editors_json.json", 'w')
fieldnames = ("Name", "Creator", "First public release", "Latest stable version", "Latest Release Date", "Programming language", "Cost (US$)", "Software license", "Open source", "CLI available", "Minimum installed size")
reader = csv.DictReader(csvfile, fieldnames)
for row in reader:
json.dump(row, jsonfile)
jsonfile.write('\n')
Nanti, anda akan memperoleh file JSON editors_json.json, dengan tampilan sebagai berikut:

Rapi kan? 🙂
4. Minta data dari 12 tabel di Wikipedia’s Comparison of Text Editors dong Gan, bisa?
Silakan Gan :), data lengkapnya bisa didownload di sini:
Tabel 2: Text editor support for various operating systems
Tabel 3: Available languages for the UI
Tabel 4: Text editor support for common document interfaces
Tabel 5: Text editor support for basic editing features
Tabel 6: Text editor support for programming features
Tabel 7: Text editor support for other programming features
Tabel 8: Text editor support for key bindings
Tabel 9: Text editor support for remote file editing over network protocols
Tabel 10: Text editor support for some of the most common character encodings
Tabel 11: Right to left (RTL) & bidirectional (bidi) support
Tabel 12: Support for newline characters in line endings
References & Further Reading
Beautiful Soup Documentation 1
Beautiful Soup Documentation 2
Big Data: What is Web Scraping and How to Use it
What’s Difference Between Web Scraping and Data Mining?
Baca Juga
 Mengintegrasikan Python dengan MySQL (Part 2) – Menyimpan Data Hasil Scraping ke Database MySQL
Mengintegrasikan Python dengan MySQL (Part 2) – Menyimpan Data Hasil Scraping ke Database MySQL Mengintegrasikan Python dengan MySQL (Part 1)
Mengintegrasikan Python dengan MySQL (Part 1) Berkenalan dengan scikit-learn (Part 9) – Beragam Strategi untuk Mengisi Missing Values
Berkenalan dengan scikit-learn (Part 9) – Beragam Strategi untuk Mengisi Missing Values Berkenalan dengan scikit-learn (Part 8) – Binarizing Label Features
Berkenalan dengan scikit-learn (Part 8) – Binarizing Label Features Array
Array 21 (2008) – A Movie Review from Data Science Perspective
21 (2008) – A Movie Review from Data Science Perspective
Founder and Nurturer of hkaLabs, who strive to become a polymath.
Pingback: Mengintegrasikan Python dengan MySQL (Part 2) – Menyimpan Data Hasil Scraping ke Database MySQL – Just Type and Run
bagi folder csv nya dong soalnya aku gabisa
Halo Abadi, terima kasih sudah berkunjung
Scroll ke atas sedikit aja Mas, di bagian “Bonus”, di poin ke-4 (tepat di atasnya “References & Further Reading”), itu sudah lengkap link download untuk 12 file csv hasil scraping.